꼬들 개선 프로젝트 - 뉴들 개발기 (1)
개요
최근 "꼬들"이라는 웹 게임을 즐겨하던 중, 문득 이 게임이 어떻게 만들어졌는지 궁금해져 리버스 엔지니어링을 시도해보았다.
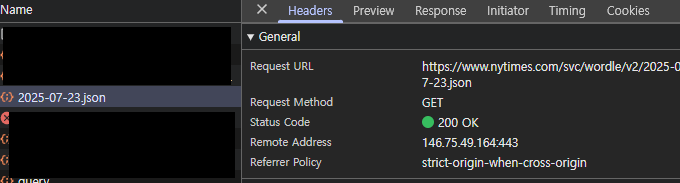
원조격인 Wordle의 경우, 매일 정답 단어를 서버에서 받아오는 구조로 되어 있어, 개발자도구의 Network 탭을 열면 매 요청마다 해당 단어를 fetch하는 내역이 포착된다.
하지만 꼬들은 이와 달리 외부 요청이 전혀 없었다.
궁금증이 더해져 난독화된 소스코드를 분석해보았고, 다행히 LLM의 도움을 받아 몇 초 만에 구조를 파악할 수 있었다.
분석 결과, 꼬들은 다음과 같은 방식으로 구성되어 있었다:
- 정답 목록과 입력 가능한 단어 목록이 각각 정수형 배열로 하드코딩되어 있음
- 기준 날짜를 설정한 뒤, 오늘 날짜와의 차이로 며칠째인지(n)를 계산
- 정답 배열에서
n mod N번째 값을 오늘의 정답으로 사용 (N은 정답 리스트의 길이) - 게임 상태(진행도 등)는 모두 브라우저의 LocalStorage에 저장되며, 별도의 서버와 통신하지 않음
이러한 구조 덕분에 꼬들은 서버 없이도 간단하게 서비스가 가능한 형태로 동작하고 있었다.
그러나 단어 풀이 고정되어 있고, 개발자가 정답 목록을 더 이상 업데이트하지 않고 있는 상태이기 때문에, 정답 리스트의 끝에 도달하면 처음부터 되풀이되는 문제가 발생하고 있었다.
이 한계를 보며, 개인적으로 이 웹사이트를 더 발전시킬 수 있겠다는 생각이 들어 꼬들의 개선판 프로젝트, <뉴들>을 시작하게 되었다.
1. 단어 받아오기

다행히 꼬들에서는 단어 출처를 명확히 명시해 두었고, 해당 링크를 통해 단어 목록을 모두 내려받아 확인해본 결과,
국립국어원의 한국어 학습용 어휘 목록 엑셀 파일을 기반으로 구성된 것을 확인할 수 있었다.
처음에는 이 파일을 그대로 가공하여 사용하려 했지만,
그럴 경우 결국 꼬들과 크게 다르지 않은 단어 풀이 되어버리기 때문에,
굳이 새로운 사이트를 만들 이유가 없다는 판단이 들었다.
이에 따라, 더 다양하고 차별화된 단어를 확보할 수 있는 새로운 단어 출처를 찾는 작업이 필요했다.
당연히 사전만큼 방대한 단어 데이터를 제공하는 곳은 드물기 때문에, 처음에는 국립국어원 표준국어대사전의 오픈 API를 활용해보려 했다.
하지만 해당 API는 개별 단어 검색만 지원할 뿐, 전체 단어 목록을 일괄적으로 받아오는 기능은 제공하지 않았다.
그래서 네이버 사전, 한국어 기초사전, 우리말샘 등 다양한 사전을 돌아다니며 대체 자료를 찾던 중, 뜻밖의 사실을 알게 되었다.
바로 표준국어대사전에서 '사전 전체 내려받기' 기능을 공식적으로 제공하고 있었던 것이다.
게다가 JSON 파일 형태로도 배포되고 있어, 별도의 크롤링이나 파싱 없이도 데이터를 바로 가공할 수 있는 이상적인 형태였다.
2. 단어 가공하기
총 43만 개에 달하는 방대한 단어 데이터를 확보했으니, 이제 이 데이터를 가공해 게임에 필요한 형태로 정제하는 작업이 필요했다.
꼬들 게임의 특성상, 단어는 초성, 중성, 종성으로 완전히 분리되어 "ㄷㅏㄴㅇㅓ"와 같은 형태로 표현된다. 이때 ㄲ, ㅉ과 같은 겹자음이나 ㅖ, ㅙ 같은 겹모음도 각각의 단순 자모로 쪼개야 하므로, 이를 우선적으로 처리해주는 변환 작업이 필요했다.
단어를 분리하는 데에는 파이썬의 jamo 라이브러리를 활용했고, 겹자음·겹모음 분리는 별도의 매핑 딕셔너리를 통해 처리하였다:
COMPOUND = {
"ㅐ": "ㅏㅣ", "ㅔ": "ㅓㅣ", "ㅚ": "ㅗㅣ", "ㅟ": "ㅜㅣ", "ㅢ": "ㅡㅣ",
"ㅘ": "ㅗㅏ", "ㅝ": "ㅜㅓ", "ㅙ": "ㅗㅏㅣ", "ㅞ": "ㅜㅓㅣ",
"ㅒ": "ㅑㅣ", "ㅖ": "ㅕㅣ",
"ㄲ": "ㄱㄱ", "ㄸ": "ㄷㄷ", "ㅃ": "ㅂㅂ", "ㅆ": "ㅅㅅ", "ㅉ": "ㅈㅈ",
"ㄳ": "ㄱㅅ", "ㄵ": "ㄴㅈ", "ㄶ": "ㄴㅎ", "ㄺ": "ㄹㄱ", "ㄻ": "ㄹㅁ",
"ㄼ": "ㄹㅂ", "ㄽ": "ㄹㅅ", "ㄾ": "ㄹㅌ", "ㄿ": "ㄹㅍ", "ㅀ": "ㄹㅎ", "ㅄ": "ㅂㅅ",
}이러한 방식으로 단어를 모두 분해하고 변환한 뒤, 게임에 사용 가능한 글자 수 조건(4/6/12자)에 맞는 단어 중에서 품사가 '명사'인 단어만 선별하여, 최종적으로 JSON 파일로 저장하였다.
{
"ㅂㅏㄹㅗ": {
"word": "바로",
"definition": "고대 로마의 철학자·저술가(B.C.116~B.C.27). 로마 최초의 공공 도서관장으로 역사, 지리, 법학, 문학, 의학, 건축의 여러 분야에 걸쳐 연구하였다. 저서에 ≪농업론≫ 따위가 있다."
}
}또한, 게임 종료 후 정답과 함께 단어의 뜻도 함께 보여줄 수 있도록, 각 단어에 definition 필드를 추가하여 의미 정보를 함께 저장하였다.
최종적으로 조건에 맞게 저장된 단어 수는 다음과 같다:
words_4.json: 3437 words
words_6.json: 35521 words
words_12.json: 10443 words정답 단어 개수
이처럼 충분한 양의 단어가 확보되었기 때문에, 지금처럼 하루에 한 단어씩 제공하는 방식으로 운영할 경우, 각각 약 9년, 97년, 28년 이상 사용할 수 있다.
이 데이터를 DB에 저장하는 방식도 고려해보았으나,
단어 목록 자체가 변경될 일이 거의 없는 정적인 데이터이고,
입력 가능한 단어 목록을 제공하는 API에서는 전체 데이터를 매번 SELECT 해서 자모만 뽑아내야 하는 구조였기 때문에,
DB를 사용하는 것보다 정적인 JSON 파일로 제공하는 것이 훨씬 효율적이라는 판단을 내렸다.
3. 운영 방식 선택
이번 프로젝트는 오라클 클라우드의 프리티어 서버(A1.Flex)를 활용하고 있다.
소규모 서비스에는 1GB 메모리를 가진 ARM 서버만으로도 충분하다고 판단했고,
오라클 프리티어는 월 비용 없이도 꽤 안정적인 서버 환경을 구축할 수 있어 개인 프로젝트에 매우 적합했다.
처음에는 프론트와 백을 모두 이 VM 하나에서 운영할까 고민했지만,
사용자가 많아졌을 때 메모리 부족이나 응답 지연과 같은 리소스 병목이 발생할 수 있다는 우려가 있었다.
그래서 다음과 같은 구조로 나누기로 결정했다:
- 프론트엔드는 HTML/CSS/JS로 이루어진 정적 파일만 존재하므로,
닷홈 웹호스팅을 활용해 정적으로 배포 - 백엔드 API 서버와 MySQL 데이터베이스는 오라클 클라우드 VM에서 운영
- 프론트엔드는 HTML/JS/CSS로 이루어진 정적 파일이 전부이기 때문에,
별도 서버 리소스 없이도 배포가 가능한 닷홈 웹호스팅을 이용해 정적으로 호스팅 - 백엔드(API 서버)와 데이터베이스(MySQL)는 직접 제어가 가능한 오라클 클라우드 VM에서 운영
이렇게 구성하면 정적 리소스는 빠르고 안정적으로 제공할 수 있고,
서버 자원은 API 처리와 데이터 저장에 집중할 수 있어 전체적인 성능과 안정성 모두를 확보할 수 있다.
무엇보다도, 이 모든 구성이 무료 티어 내에서 충분히 운영 가능하다는 점이 가장 큰 장점이다.
4. 개발 언어/프레임워크
필자는 이전에도 여러 차례 React 기반의 프론트엔드 프로젝트를 진행한 경험이 있다.
그래서 이번에는 Vue나 Svelte처럼 다른 프레임워크를 사용해보며 새로운 시도를 해볼까 생각했었다.
하지만 기반이 된 꼬들 게임의 깃허브 레포지토리(AnyLanguage-Word-Guessing-Game)가 이미 React 기반으로 구성되어 있었고, 이를 그대로 포크해서 활용하는 방식이 가장 효율적이었다.
결국 반 강제로 React를 다시 사용하게 되었지만,
익숙한 만큼 구조를 빠르게 파악하고 커스터마이징할 수 있었던 점은 오히려 장점이었다.
백엔드는 NestJS를 선택했다.
NestJS는 TypeScript 기반의 백엔드 프레임워크로, 모듈화된 구조와 의존성 주입, 명확한 라우팅 구조를 가지고 있어 규모가 커지더라도 유지보수가 쉬운 구조를 제공한다.
무엇보다도 Java의 Spring 프레임워크와 구조적으로 매우 유사하기 때문에,
향후 Spring을 학습할 때도 큰 이질감 없이 자연스럽게 전이할 수 있을 것 같다는 점이 NestJS를 선택한 주요 이유였다.
마치며
이번 글에서는 꼬들을 분석하고, 이를 바탕으로 개선판 웹 게임 뉴들을 기획하고 준비하는 과정까지를 정리해보았다.
다음 글에서는 본격적인 구현 과정과 실제로 마주친 문제들, 그리고 그 해결 방법들에 대해 더 자세히 소개할 예정이다.